
 Steeds meer IT ‘dingen’ gaan, schijnbaar, automatisch vanzelf. Mooi flitsende websites en smartphone apps welke vaak praktisch en bruikbaar zijn. Om deze websites en apps van data te voorzien moet er vaak heel wat gebeuren. Denk hierbij aan het overhalen van bepaalde data bestanden of records uit verschillende databases enzovoorts. Tevens dient er vaak nog het nodige omgezet/vertaald te worden (transformatie). Deze acties gebeuren al heel lang en zullen ook nog wel heel lang uitgevoerd moeten worden (vermoed ik). Waar dat ‘vroeger’ aan elkaar hing van de nodige batch/bash scripts zijn er tegenwoordig mooie tools welke dit ‘aan elkaar knoop werk’ voor je kunnen faciliteren.
Steeds meer IT ‘dingen’ gaan, schijnbaar, automatisch vanzelf. Mooi flitsende websites en smartphone apps welke vaak praktisch en bruikbaar zijn. Om deze websites en apps van data te voorzien moet er vaak heel wat gebeuren. Denk hierbij aan het overhalen van bepaalde data bestanden of records uit verschillende databases enzovoorts. Tevens dient er vaak nog het nodige omgezet/vertaald te worden (transformatie). Deze acties gebeuren al heel lang en zullen ook nog wel heel lang uitgevoerd moeten worden (vermoed ik). Waar dat ‘vroeger’ aan elkaar hing van de nodige batch/bash scripts zijn er tegenwoordig mooie tools welke dit ‘aan elkaar knoop werk’ voor je kunnen faciliteren.
Bij een van mijn klussen kwam ik bij een klant over de vloer die gebruik maakt van een pentaho product. Pentaho heeft ook een opensource/community edition Kettle-Data Integration genaamd. Het product is een zogenaamde Extraction, Transformation and Loading (ETL) tool. Oftewel extraheren, transformeren en laden. Acties welke vaak nodig zijn om die mooie website/app mogelijk te maken 🙂
Installatie en starten
Via de Kettle website kan een pdi-ce-7.1.0.0-12.zip (of andere versie) van zo’n 882 Mb worden gedownload. Deze zip heb ik vervolgens op m’n Debian werkstation gezet en uitgepakt. De installatie instructies zijn vrij rechttoe-rechtaan en staan onderaan op deze pagina. Nadat de zip is uitgepakt is het een kwestie van cd data-integration en ./spoon.sh en de grafische toolbox zal worden gestart.
Jobs en Transformaties
De tool wordt overigens geleverd met veel voorbeelden in de data-integration/samples map. Altijd handig om eens te kijken hoe bepaalde zaken aangepakt kunnen worden. Ik houd er altijd van om eerst eenvoudig/simpel te beginnen. Dus gewoon een bepaalde directory ‘monitoren’ op *.csv bestanden en vervolgens transformeren naar een *.xml bestand. Hé ik had toch gezegd simpel beginnen 🙂 Uiteindelijk is de transformatie uit een 3-tal stappen gaan bestaan:
- scan een directory op *.csv bestanden
- open een csv bestand
- transformeer het csv bestand naar een xml bestand
 Vervolgens wilde ik teveel ‘procesmatige’ acties in de transformatie stoppen, bijvoorbeeld het input bestand verplaatsen als de transformatie gelukt was. Dat lukte niet echt. Achteraf logisch, want deze actie past natuurlijk beter in een job. Uiteindelijk is de job een groter geheel waar de transformatie maar een onderdeel van is.
Vervolgens wilde ik teveel ‘procesmatige’ acties in de transformatie stoppen, bijvoorbeeld het input bestand verplaatsen als de transformatie gelukt was. Dat lukte niet echt. Achteraf logisch, want deze actie past natuurlijk beter in een job. Uiteindelijk is de job een groter geheel waar de transformatie maar een onderdeel van is.

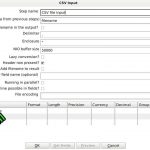
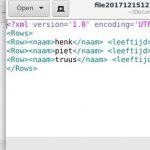
Zowel de transformaties als jobs kunnen eenvoudig in de Spoon GUI (Graphical User Interface) worden uitgevoerd. Per transformatie/job actie kan er heel veel worden geconfigureerd. Dus per blokje moet je natuurlijk de bepaalde stap configureren.
Uitvoeren vanaf de command line
De Jobs kunnen uitgevoerd worden vanuit de Spoon GUI maar kunnen ook via het kitchen script. Hieronder wordt het kitchen shell script gestart en wordt de Job file meegegeven. Dit resulteert in het uitvoeren van de Job. In de Job zelf heb ik aangegeven dat om de 10 seconden de uitvoering gestart moet worden en dit herhaald. Je kan er ook natuurlijk voor kiezen om de scheduling uit de job te halen en dit via bijvoorbeeld de Linux crontab of Windows taskscheduler te doen.
./kitchen.sh -file ../kettle-data/TestJob1.kjb

Conclusie
De Kettle Data Integration is echt een waar ‘zwitsers zakmes’ en zeer veelzijdig. Bij mijn 1e kennismaking krabbel je natuurlijk maar aan de oppervlakte van alle mogelijkheden. Maar het feit dat deze tool bij een productiebedrijf in gebruik is en de vele transformatie opties, zal deze tool in menig DevOps omgeving niet misstaan.